RESEARCH
Selected Projects
BRIO: Bringing Order to Abstractive Summarization, ACL 2022
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization, ACL 2021
RefSum: Refactoring Neural Summarization, NAACL 2021
On Learning Text Style Transfer with Direct Rewards, NAACL 2021
BRIO: Bringing Order to Abstractive Summarization
Yixin Liu, Pengfei Liu, Dragomir Radev, Graham Neubig
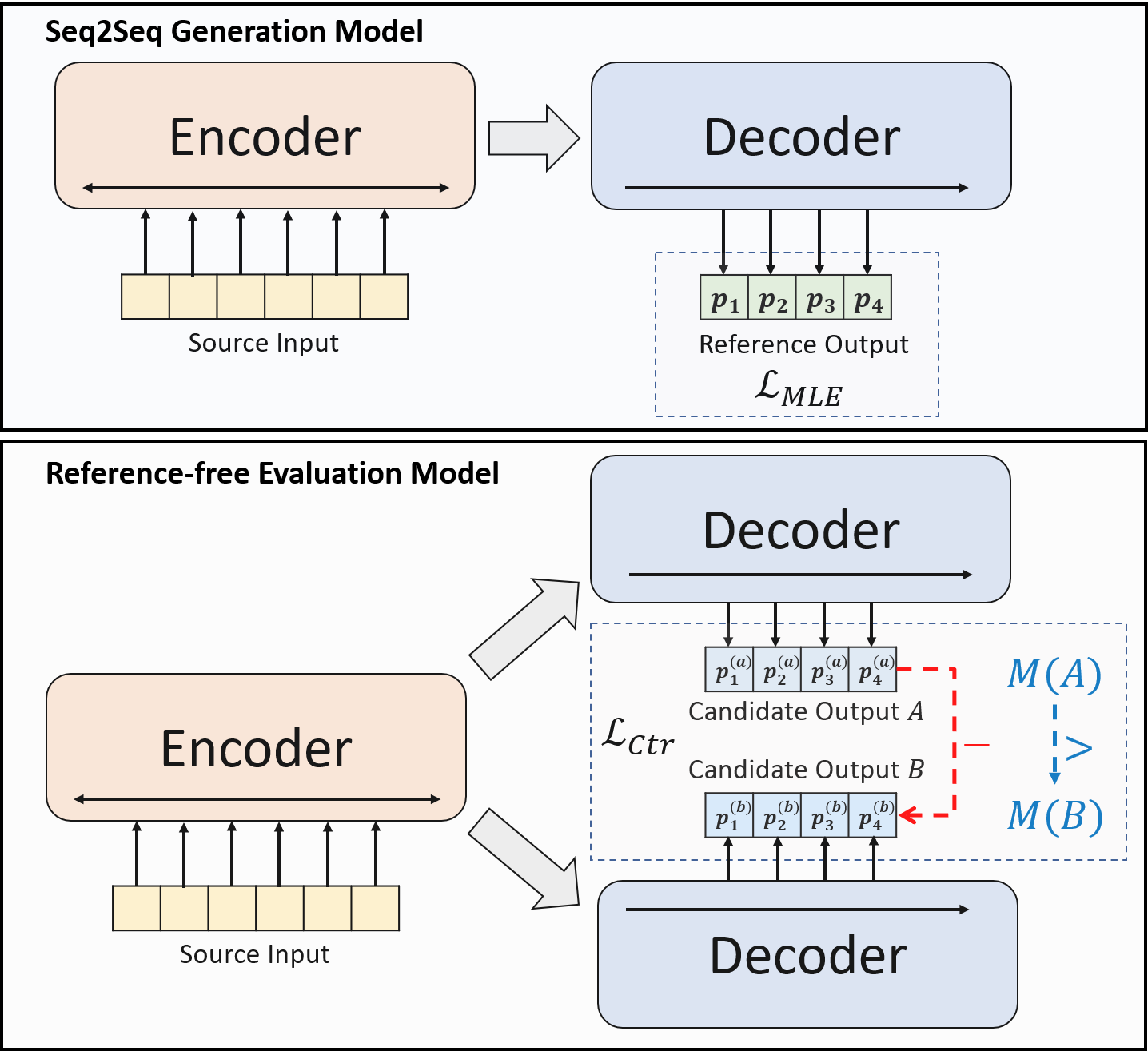
Abstractive summarization models are commonly trained using maximum likelihood estimation, which assumes a deterministic (one-point) target distribution in which an ideal model will assign all the probability mass to the reference summary. This assumption may lead to performance degradation during inference, where the model needs to compare several system-generated (candidate) summaries that have deviated from the reference summary. To address this problem, we propose a novel training paradigm which assumes a non-deterministic distribution so that different candidate summaries are assigned probability mass according to their quality. Our method achieves a new state-of-the-art result on the CNN/DailyMail (47.78 ROUGE-1) and XSum (49.07 ROUGE-1) datasets. Further analysis also shows that our model can estimate probabilities of candidate summaries that are more correlated with their level of quality.
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
Yixin Liu, Pengfei Liu
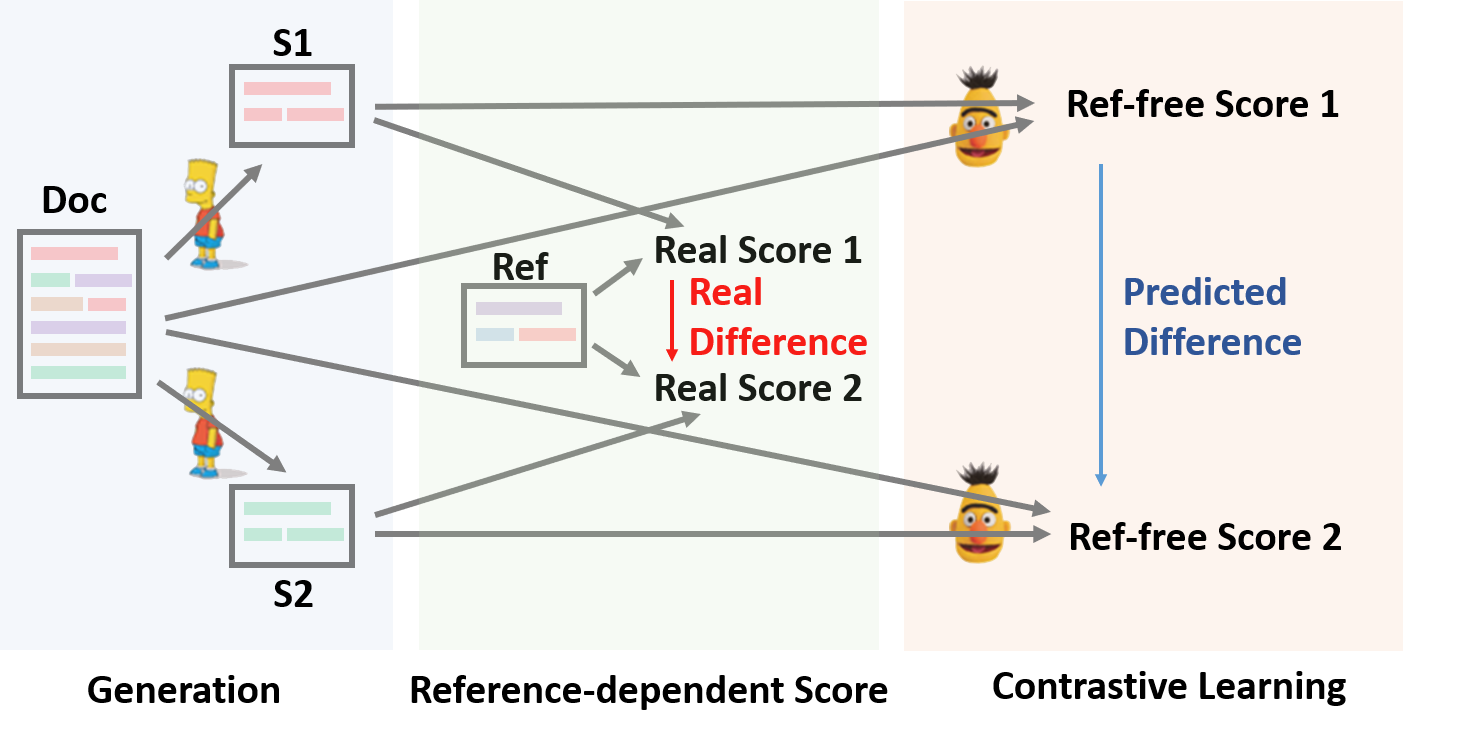
In this paper, we present a conceptually simple while empirically powerful framework for abstractive summarization, SimCLS, which can bridge the gap between the learning objective and evaluation metrics resulting from the currently dominated sequence-to-sequence learning framework by formulating text generation as a reference-free evaluation problem (i.e., quality estimation) assisted by contrastive learning.
Experimental results show that, with minor modification over existing top-scoring systems, SimCLS can improve the performance of existing top-performing models by a large margin.
Particularly, 2.51 absolute improvement against BART and 2.50 over PEGASUS w.r.t ROUGE-1 on the CNN/DailyMail dataset, driving the state-of-the-art performance to a new level.
RefSum: Refactoring Neural Summarization
Yixin Liu, Zi-Yi Dou, Pengfei Liu
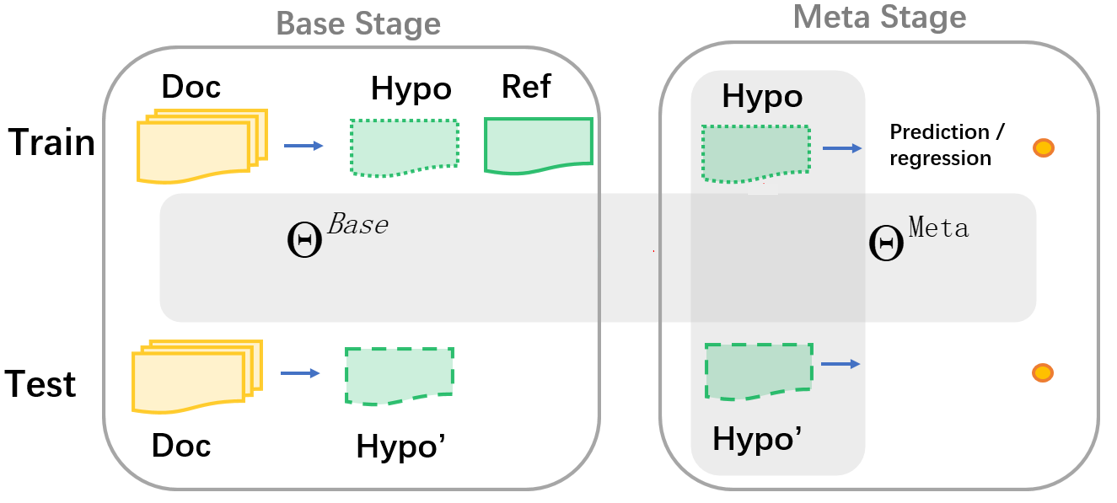
Although some recent works show potential complementarity among different state-of-the-art systems, few works try to investigate this problem in text summarization. Researchers in other areas commonly refer to the techniques of reranking or stacking to approach this problem. In this work, we highlight several limitations of previous methods, which motivates us to present a new framework Refactor that provides a unified view of text summarization and summaries combination. Experimentally, we perform a comprehensive evaluation that involves twenty-two base systems, four datasets, and three different application scenarios. Besides new state-of-the-art results on CNN/DailyMail dataset (46.18 ROUGE-1), we also elaborate on how our proposed method addresses the limitations of the traditional methods and the effectiveness of the Refactor model sheds light on insight for performance improvement.
Our system can be directly used by other researchers as an off-the-shelf tool to achieve further performance improvements. We open-source all the code and a convenient interface to use it.
On Learning Text Style Transfer with Direct Rewards
Yixin Liu, Graham Neubig, John Wieting
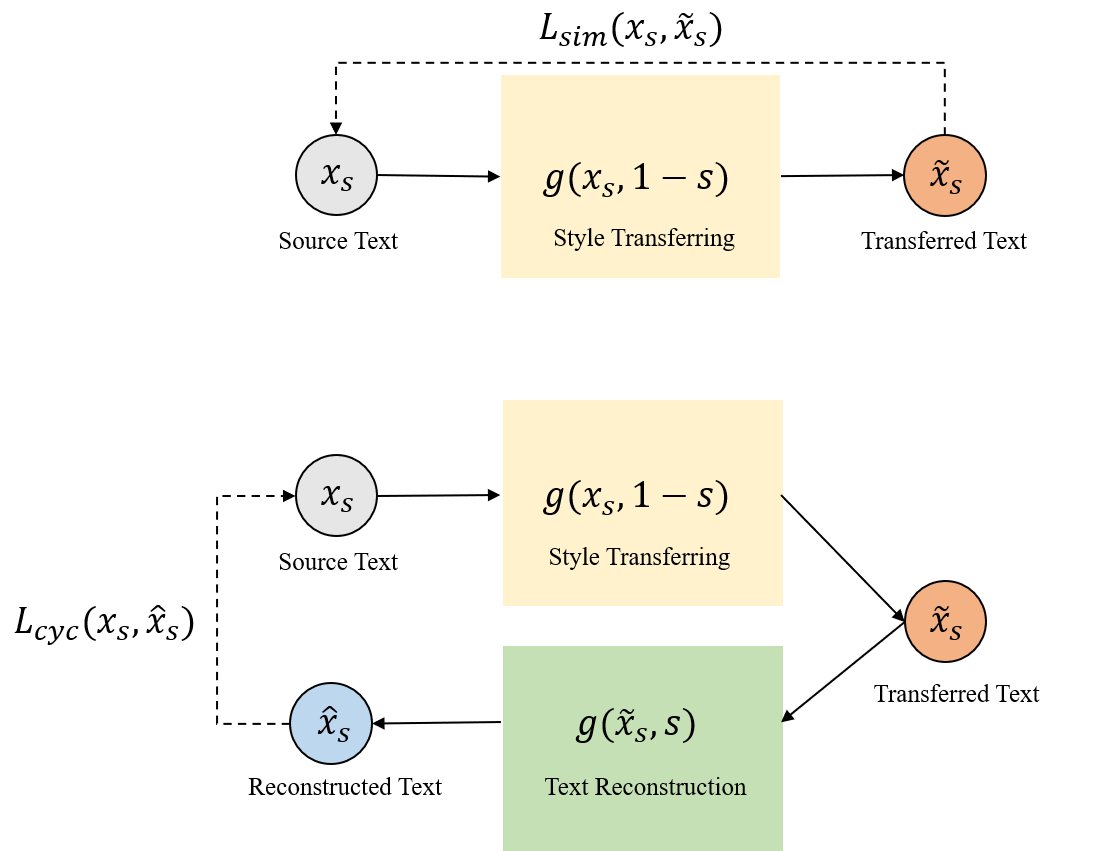
In most cases, the lack of parallel corpora makes it impossible to directly train supervised models for the text style transfer task. In this paper, we explore training algorithms that instead optimize reward functions that explicitly consider different aspects of the style-transferred outputs. In particular, we leverage semantic similarity metrics originally used for fine-tuning neural machine translation models to explicitly assess the preservation of content between system outputs and input texts. We also investigate the potential weaknesses of the existing automatic metrics and propose efficient strategies of using these metrics for training. The experimental results show that our model provides significant gains in both automatic and human evaluation over strong baselines, indicating the effectiveness of our proposed methods and training strategies.